

Building Production-Ready Performance Prediction Systems: From Notebook to Network
Let's productionize our experimental models into robust prediction systems that automatically prevent performance issues before they impact users.


Notebook to Network?
You've built and tested machine learning models that predict API performance beautifully in notebooks. They have clean data, perfect predictions, and gorgeous visualizations. But there's that million dollar question:
How do I actually put this into production?
It's a question I wrestled with too. You see, like many engineers, I had to learn the hard way that a perfect R² score means nothing if your model can't handle real-world traffic surges, data anomalies, or infrastructure hiccups.
Let's imagine a scenario most of us have either experienced or fear: You've just deployed your first prediction model to production. Everything looks great in testing. Your colleagues are impressed. Then Friday evening hits, traffic spikes, and instead of preventing performance issues, your prediction pipeline becomes another point of failure.
What seemed straightforward in a notebook becomes treacherous in production. Your pristine model now faces:
Unpredictable data quality and availability
Real-time processing constraints
System resource limits
Infrastructure failures
Scaling challenges
Today, we'll bridge that gap. Using synthetic but realistic scenarios, we'll build a robust prediction system that can handle production's messy reality.
Production Ready System
Architecture of a Performance Prediction System
Let's start with the architecture of a production-ready prediction system.
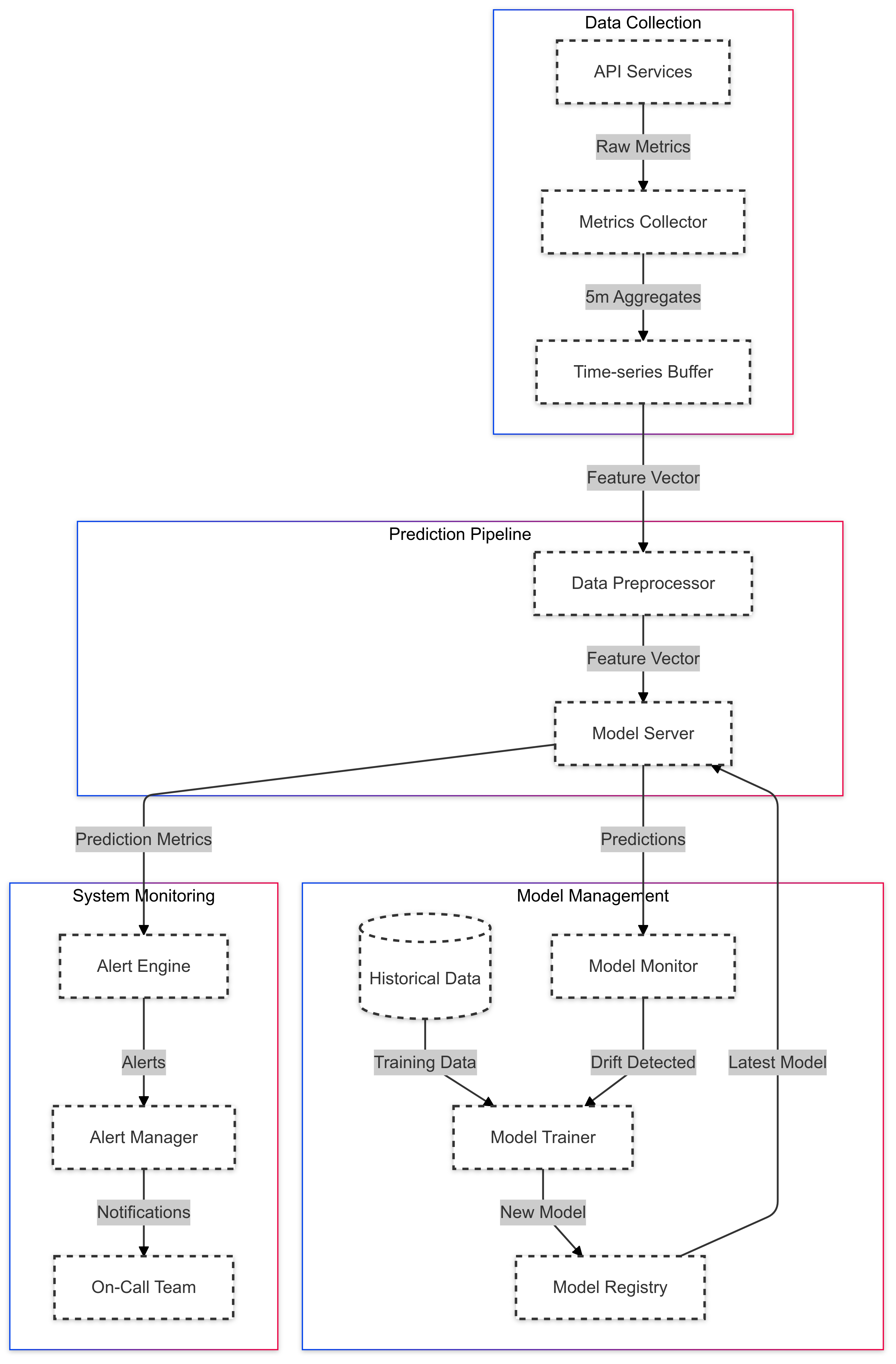
Looking at our system architecture diagram, each component plays a vital role in transforming experimental models into reliable production services. The data collection layer aggregates metrics from our API services into 5-minute windows, providing a stable foundation for predictions. This time-series data feeds into our prediction pipeline, where the preprocessor normalizes and validates incoming metrics before passing them to the model server.
The monitoring system works in parallel, analyzing both prediction accuracy and system health. When model drift is detected, it triggers retraining using historical data, while the alert engine manages notification thresholds. This closed-loop system ensures our predictions remain accurate as traffic patterns evolve.
Code For The Performance Prediction System
Let's look at how we implement these components, starting with the metrics collection pipeline...
class MetricsCollector:
def __init__(self, buffer_size=300): # 5 minutes of per-second data
self.metrics = deque(maxlen=buffer_size) # Built-in overflow protection
self._lock = asyncio.Lock() # Thread safety
async def collect(self):
async with self._lock:
try:
# Collect with timeout
async with timeout(0.5):
raw_metrics = await self._fetch_metrics()
# Validate before storing
if self._validate_metrics(raw_metrics):
self.metrics.append(raw_metrics)
return True
except TimeoutError:
logger.warning("Metric collection timed out")
return FalseThis implementation provides several layers of protection against common production issues. Network timeouts are handled gracefully without blocking the pipeline, while data validation ensures only clean metrics enter our system. The bounded buffer prevents memory issues during traffic spikes, and the thread-safe design allows multiple collectors to operate in parallel. Let's examine how these raw metrics flow through our prediction pipeline...
Raw metrics first enter our DataPreprocessor, which transforms them into feature vectors suitable for our model. The preprocessor handles several critical tasks:
def create_feature_vector(self, metrics: List[APIMetric]) -> pd.DataFrame:
df = pd.DataFrame([self._metric_to_dict(m) for m in metrics])
# Calculate derived metrics
df['error_rate'] = df['error_count'] / df['request_count']
# Add temporal context
df['hour'] = df['timestamp'].dt.hour
df['day_of_week'] = df['timestamp'].dt.dayofweek
# Calculate rolling means for stability
for col in ['latency_ms', 'cpu_usage', 'memory_usage']:
df[f'{col}_rolling_mean'] = df[col].rolling(
window=self.window_size,
min_periods=1
).mean()The preprocessor enriches our raw metrics with temporal context and rolling averages, which help capture trends and patterns in the data. This processed data then flows to our ModelServer, which generates predictions with confidence intervals:
def predict(self, features: pd.DataFrame) -> List[PredictionResult]:
predictions = []
for _, row in features.iterrows():
point_pred = self.model.predict(row.values.reshape(1, -1))[0]
# Calculate prediction uncertainty
residuals = np.std([
tree.predict(row.values.reshape(1, -1))[0]
for tree in self.model.estimators_
])
ci_width = 1.96 * residuals
predictions.append(PredictionResult(
predicted_latency=point_pred,
confidence_interval=(point_pred - ci_width, point_pred + ci_width)
))The model server maintains versioning information and can be updated without service interruption. When model drift is detected, a new model can be trained on recent data while the current model continues serving predictions.
The monitoring system closes the feedback loop by tracking prediction accuracy and system health metrics. It maintains rolling windows of prediction errors and can trigger model retraining when accuracy drops below configured thresholds.
Do take the code for a good spin. (source)
In the next section, we'll explore how to deploy this system to production environments, including considerations for scaling, monitoring, and maintenance.
Deploying API Prediction Model to Production
Let's look at practical considerations for deploying this prediction system to production.
Resource allocation requires careful planning based on your metrics volume. A good starting point is to size your prediction service instances with at least 2 CPU cores and 4GB RAM, which comfortably handles up to 1000 predictions per minute. The model server maintains prediction latencies under 100ms with this configuration, leaving adequate headroom for traffic spikes.
One often-overlooked aspect is environment configuration. While development environments can use default settings, production deployments need explicit configuration for:
Feature calculation windows (typically 1 hour of data)
Model update intervals (usually daily during low traffic)
Cache sizes for frequently accessed metrics
Connection pool sizes for dependent services
The model server's memory usage grows with the size of your historical data window. A practical approach is to retain 2 weeks of metrics for immediate access, with older data archived to cold storage. This balances prediction accuracy against resource consumption.
Load balancing requires special attention. Unlike stateless web services, prediction servers need sticky sessions during model updates. Configure health checks to verify both service availability and prediction quality. A prediction server should be considered unhealthy if its error rate exceeds 5% or if prediction latency consistently exceeds 200ms.
For monitoring, focus on metrics that directly impact business operations:
Prediction error rates compared to actual latencies
Model refresh success rates and timings
Feature calculation pipeline health
Correlation between predicted and actual API performance
Production incidents commonly stem from data quality issues rather than model accuracy. Common scenarios include:
Missing metrics during infrastructure updates
Clock skew between metric sources
Network latency affecting feature calculations
Resource exhaustion during high-traffic periods
Establish clear maintenance windows for model updates. Schedule these during periods of stable traffic, and maintain at least one previous model version for quick rollbacks. Archive model artifacts alongside their training data and performance metrics to aid in debugging.
Regular validation ensures prediction quality remains consistent. Key validation metrics include:
Mean absolute percentage error (MAPE) of latency predictions
False positive rate for high-latency predictions
Distribution of prediction confidence intervals
Feature importance stability across retraining cycles
Data retention policies should align with your business requirements. For most applications, retaining:
2 weeks of raw metrics
3 months of aggregated data
1 year of model performance metrics provides adequate historical context while remaining manageable.
Common operational issues and their solutions deserve careful consideration. Model drift often manifests gradually - rising prediction errors or widening confidence intervals signal the need for retraining before serious issues occur. Regular comparison of feature distributions helps identify potential problems early.
When rolling out model updates, use gradual traffic shifting. Start with 10% of traffic, monitor for any degradation, then slowly increase if metrics remain stable. This approach minimizes the impact of potential issues while providing clear validation of model performance.
Documentation and runbooks should focus on operational procedures rather than theory. Include step-by-step guides for:
Validating model updates
Investigating prediction anomalies
Performing emergency rollbacks
Recovering from data pipeline failures
Two critical aspects often separate reliable ML systems from fragile ones: graceful shutdowns and drift detection. Let's explore how to implement these effectively in production.
Graceful shutdowns ensure your prediction service can be updated without dropping requests. The model server needs to track active predictions and stop accepting new requests during shutdown. It should wait for in-flight predictions to complete, but with a reasonable timeout to prevent hanging. This prevents disruption during deployments and maintains service reliability.
Version rollbacks are equally important. Your model server should maintain multiple model versions and support atomic version switches. When rolling back, it's crucial to verify the previous version is healthy before fully switching traffic. This might mean running both versions briefly and comparing their predictions to ensure the rollback won't cause additional issues.
Model drift detection requires continuous monitoring of prediction quality. Instead of just tracking simple metrics, implement a sliding window approach that:
Maintains recent prediction-actual pairs
Calculates error metrics over time
Detects concerning trends in accuracy
Uses both absolute thresholds and trend analysis
The monitoring system should detect drift through multiple signals. A sudden increase in prediction errors might indicate immediate problems, but gradually increasing errors often signal model drift. By tracking both patterns, you can catch issues before they become critical.
When implementing these monitoring components:
Choose window sizes that match your traffic patterns
Set drift thresholds based on business impact
Configure automated alerts for drift detection
Maintain detailed audit logs of model changes
Remember that monitoring isn't just about detecting issues - it's about understanding your system's behavior over time. Regular analysis of these metrics helps inform future model improvements and system optimizations.
Simplicity in production systems pays dividends. While sophisticated modeling techniques might improve accuracy marginally, the operational complexity they add rarely justifies the benefit. Focus on robust, maintainable implementations that solve real business problems reliably.
In our next article, we will explore an elusive aspect of APIs in the context of production reliability.
What’s beyond predictions?