Elegance of the Unix Shell & Adopting the Pipeline Architecture Style in Everyday Programming

Table of Contents
The pipeline architecture style is one to look at curiously, but before we jump into it or what use does it have in everyday programming, let’s visit a famous story from the past that establishes the elegance of the Unix shell.
Programming Pearls from History #
The Association for Computing Machinery(ACM) was founded as the Eastern Association for Computing Machinery at a meeting at Columbia University in New York on September 15, 1947. Since 1958, ACM has been publishing a magazine called “The Communications of ACM”. It is undoubtedly the flagship magazine of the 100,000-member-strong organization. In 1986, Jon Bentley, who wrote the column - “Programming Pearls” in the magazine, invited Donald Knuth (yes, the same Don Knuth of knuth-morris-pratt fame) to write a literal program that could figure out the solution to a problem he posed:
Given a text file and an integer k, print the k most common words in the file (and the number of their occurrences) in decreasing frequency.
Knuth wrote a program combining Pascal and TEX that was over 8 pages long and had over 40 steps in the algorithm. It is too large to include here, but you can find it in the original column. Bentley had also invited Doug McIlroy, the genius mathemetician/engineer/programmer who is credited with the invention of Unix pipes to critique Knuth’s program.
In response to Knuth’s massive program, McIlroy wrote six commands joined by pipes to do the absolute same thing!
tr -cs A-Za-z '\n' |
tr A-Z a-z |
sort |
uniq -c |
sort -rn |
sed ${1}q
For those unfamiliar with the magic of the shell, he also wrote what each of those commands did:
1. Make one-word lines by transliterating the complement (-c) of the alphabet into newlines (note the quoted newline), and squeezing out (-s) multiple newlines.
2. Transliterate upper case to lower case.
3. Sort to bring identical words together.
4. Replace each run of duplicate words with a single representative and include a count (-c).
5. Sort in reverse (-r) numeric (-n) order.
6. Pass through a stream editor; quit (q) after printing the number of lines designated by the script’s first parameter (${1}).
This incident has become part of computer science folklore and you will probably find hundreds of articles and blogs all over the internet drawing humor from the same incident, majorly at the expense of Knuth. While the criticism of Knuth for writing the program he was asked to write is completely unfair and it is best to forget the incident in that light, the powerfully elegant idea of pipes & filters and the wizardry they enable is worth remembering.
Pipeline Architecture - Usage of the Term across Fields of Study #
Wikipedia has separate articles for Pipeline(Unix) & Pipeline(software). The reason for disambiguating in this fashion is perhaps the similarity in behavior & the spread of concepts into other areas within the field of computer science.
For example, this paper written by C.V. Ramamoorthy & H.F Li in 1977, born out of a research sponsored by the US Army, talks of Pipelined Computer Architecture in the context of designing computer hardware systems. The definition given by the authors at the start of the paper does little to help with our ambiguity problem.
Pipelining is one form of imbedding parallelism or concurrency in a computer system. It refers to a segmentation of a computational process (say, an instruction) into several subprocesses which are executed by dedicated autonomous units (facilities, pipelining segments). Successive processes (instructions) can be carried out in an overlapped mode analogous to an industrial assembly line.
Interestingly, another such term - “Communicating Sequential Processes” receives a clarification and a blanket cover to be used across industries. From Wikipedia:
CSP was first described in a 1978 article by Tony Hoare, but has since evolved substantially. CSP has been practically applied in industry as a tool for specifying and verifying the concurrent aspects of a variety of different systems, such as the T9000 Transputer, as well as a secure ecommerce system.
What makes it even more interesting is that Tony Hoare credits the basis of his paper to McIlroy. Doug McIlroy had come up with Pipes much before the advent of Unix itself. This typewritten note from 1964 quite effectively proves that.

Whatever be the definition, we will not strive for accuracy in describing or categorizing pipelines. Continuing tradition from earlier posts about modularity and architectural quanta, we’ll trust Mark & Neal for terminology. Thus, we will refer to the general theory as the Pipeline Architecture Style.
The Pipeline Architecture Style #
The pipeline architecture style usually consists of filters that are connected via pipes usually in a point-to-point fashion.
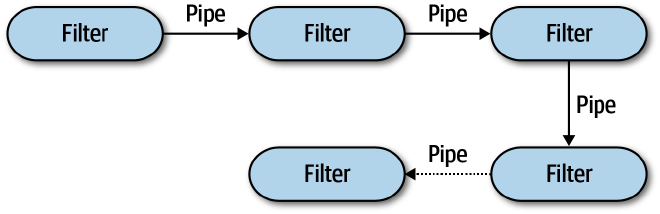
Here’s how Fundamentals of Software Architecture describes the style.
Pipes #
Pipes in this architecture form the communication channel between filters. Each pipe is typically unidirectional and point-to-point (rather than broadcast) for performance reasons, accepting input from one source and always directing output to another. The payload carried on the pipes may be any data format, but architects favor smaller amounts of data to enable high performance.
Filters #
Filters are self-contained, independent from other filters, and generally stateless. Filters should perform one task only. Composite tasks should be handled by a sequence of filters rather than a single one.
Four types of filters exist within this architecture style:
- Producer: The starting point of a process, outbound only, sometimes called the source.
- Transformer: Accepts input, optionally performs a transformation on some or all of the data, then forwards it to the outbound pipe. Functional advocates will recognize this feature as map.
- Tester: Accepts input, tests one or more criteria, then optionally produces output, based on the test. Functional programmers will recognize this as similar to reduce.
- Consumer: The termination point for the pipeline flow. Consumers sometimes persist the final result of the pipeline process to a database, or they may display the final results on a user interface screen.
For an architecture style otherwise called pipes-and-filters pattern, there is little that we can add to the definitions provided by the authors. We will move to thinking of and working with programs as pipelines with the help of Go.
Programs as Pipelines (In Go) #
British programmer and author, John Arundel, who runs a Go mentoring company called Bitfield Consulting came up with a novel idea as part of one of his books to make standard task chaining in Go as easy as it was shell. He called his program simply - script. The name is apt for something that enables command chaining. And the concept is similar to Unix pipes.
Taking from an example he’s posted on his blog, say you had a file structured like this:
203.0.113.17 - - [30/Jun/2019:17:06:15 +0000] "GET / HTTP/1.1" 200 2028 "https://example.com/ "Mozilla/5.0...
..and you needed to find the IPs (first column) sorted by the frequency they appear in the file, in bash you would write something like this:
cut -d' ' -f 1 access.log |sort |uniq -c |sort -rn |head
To achieve the same result via a high level programming language, here are the steps it would take you:
- Open the file.
- Instantiate a buffered scanner by passing the file descriptor.
- Scan the file and extract the first element into a map of IP and count of occurences.
- Create another structure to sort the map.
- Loop over the map and sort it by frequency of occurence for the new data structure.
- Loop over the new data structure and print the result.
Not to mention the additional errors and edge cases you’d need to handle. It is not very difficult to imagine that the resulting code would be at least 30 lines of code in a language like Java or Go.
With script, it almost becomes a command by command replacement, resulting in a clean one-liner that can be compiled into a binary file and executed much like a shell script. Here’s what it looks like:
File("log").Column(1).Freq().First(10).Stdout()
You can even chain-in native Go constructs within these pipes and not have to worry about side effects.
script.Stdin().Match("Error").FilterLine(strings.ToUpper).Stdout()
So how exactly does this work? Shell languages like Bash do not understand type but Go is a statically typed language. How are outputs from different types morphed into input of another? Turns out they don’t. All methods (i.e. commands) belong to a single type and output a pointer to the exact same type.
type Pipe struct {
// Reader is the underlying reader.
Reader ReadAutoCloser
stdout, stderr io.Writer
httpClient *http.Client
// because pipe stages are concurrent, protect 'err'
mu *sync.Mutex
err error
}
This struct containing of just 5 elements heads a single file called script.go that is 966 lines long at the time of writing this article. All other content in the files are methods belonging to this struct, so an instance of the Pipe struct has all these methods at disposal.
Consider the implementations of the Match & FilterLine methods that we used in one of the commands above.
// Match produces only the input lines that contain the string s.
func (p *Pipe) Match(s string) *Pipe {
return p.FilterScan(func(line string, w io.Writer) {
if strings.Contains(line, s) {
fmt.Fprintln(w, line)
}
})
}
// FilterLine sends the contents of the pipe to the function filter, a line at
// a time, and produces the result. filter takes each line as a string and
// returns a string as its output. See [Pipe.Filter] for concurrency handling.
func (p *Pipe) FilterLine(filter func(string) string) *Pipe {
return p.FilterScan(func(line string, w io.Writer) {
fmt.Fprintln(w, filter(line))
})
}
Since both the methods return a method called FilterScan (functions are first class citizens in Go; methods are just functions with receivers), we do not get how it turns out be a wrapped instance of a Pipe. To know this, we have to follow the method along:
// FilterScan sends the contents of the pipe to the function filter, a line at
// a time, and produces the result. filter takes each line as a string and an
// [io.Writer] to write its output to. See [Pipe.Filter] for concurrency
// handling.
func (p *Pipe) FilterScan(filter func(string, io.Writer)) *Pipe {
return p.Filter(func(r io.Reader, w io.Writer) error {
scanner := newScanner(r)
for scanner.Scan() {
filter(scanner.Text(), w)
}
return scanner.Err()
})
}
// Filter sends the contents of the pipe to the function filter and produces
// the result. filter takes an [io.Reader] to read its input from and an
// [io.Writer] to write its output to, and returns an error, which will be set
// on the pipe.
//
// filter runs concurrently, so its goroutine will not exit until the pipe has
// been fully read. Use [Pipe.Wait] to wait for all concurrent filters to
// complete.
func (p *Pipe) Filter(filter func(io.Reader, io.Writer) error) *Pipe {
if p.Error() != nil {
return p
}
pr, pw := io.Pipe()
origReader := p.Reader
p = p.WithReader(pr)
go func() {
defer pw.Close()
err := filter(origReader, pw)
if err != nil {
p.SetError(err)
}
}()
return p
}
And there you have it! FilterScan wraps Filter which in turn wraps a concurrent Go function (closure) that executes the filter function from the Go standard library and returns the same instance of the pointer to the Pipe that it originally recieved.
This is nothing but an implementation of the Builder Design Pattern, one of the original patterns by The Gang of Four.
Deconstructing a popular library is always a fun way to learn more about a language, but that aside, using shell like commands inside of Go and using them for simple processing that would otherwise consume more time is definitely a bargain one could go for in some projects. Whether, the additional overhead is worth including in your build is purely a choice one would have make depending on what’s the repository already like and where it is headed.
Additional Links #
- Similar effort in C++: Talk at CPPCon.
- Pipes in Java with Java IO.
- Python Pipe
- Scaling the pipes-and-filter architecture as a cloud design pattern - Azure Documentation
Personal Tidbit #
My first job was as a C++ programmer for an Alcatel Lucent project that managed the provisioning and configuration of a particular network element manufactured by the company. The specific role required me to develop and test new commands for the element’s command-line interface. For security or other reasons unknown to my novice earlier form, we were to ssh into few Linux boxes that were assigned to us and were within the company’s VPN; and code inside them. The IDE that I used was Vim. Coming from a Windows world at that time, it was a nightmare at first to be in the world of shells. But I quickly realized that to be efficient at this job, I had to learn unix piping commands. Spending a few weeks with freely available resources, I was able to get myself to a level where I was comfortable on the terminal. Now I started using piped commands for everything - from testing code I wrote - to finding the lines of code I had modified for filling the dreaded “modification request (MR)” form. Over the years, this knowledge has been very handy in doing stuff quickly on the terminal and has served me well in crunch moments or when debugging enterprise software - where writing a Java program would have taken a tad longer.
The fact that Doug McIlroy championed Pipelines for Unix at Bell Labs and Alcatel Lucent was the parent company of Bell Labs when I was working for them in the 2010s just happens to be a personally amusing coincidence.